|
Here is a proposed agenda for the current Mturk issue. The document also includes some updates about how many researchers have seen duplicates in their data so far. I invite comments and collaboration http://z.umn.edu/MturkIssue
8 Comments
Many of us who collected data from Mturk recently noticed an increase in duplicated GPS coordination, and we have learned from some researchers that the duplicates may produce unreliable responses. Some other scholars question whether the GPS method can actually reliable detect any unreliable responses. Others concern that the unreliable response I have seen (so far) in my data are outliers and they are wondering if the issue is pervasive. Here I propose a simple test with some specific predictions that can soon answer to these concerns.
As I have noted, the data where I initially found anomaly is still collecting data. I aimed to have a total sample size of 1500 for the study. The existing analyses are based on the first 1/3rd of my sample, as the remaining 2/3 is still being collected. One way to answer regarding the question whether GPS duplicates are pervasive and if the GPS method can detect unreliable responses is to apply my own procedure on the remains 2/3 of my data that I am collecting. I think we will have strong evidence that duplicated GPS is pervasive (as opposed to being outliers) and the GPS method can detect unreliable response if we see the following predictions come true on my remaining data that I will finish collecting. I welcome thoughts and comments on regarding these predictions that I will be able to test when my data collection is finished . Testing the question of pervasiveness So far my impression from the survey here is that the duplicates are becoming more and more common in matter of weeks. In my own existing data with 578 participants, I have noticed about half (!!!) are from duplicates. I would think half of contaminated data is pervasive. If I predict that in the remaining 1000 responses there are about 500 response (if not more) from duplicates, I think it is a strong evidence that the duplicates are rampant, at least in my own data. Testing the question of data quality I think if we see the following predictions are preponderantly supported, then we have strong evidence that data from duplicates are unreliable. 1. The reliability of known scales I will test the reliability of the racial identification scale that I used for duplicates and non-duplicates separately based on what I saw in the 1/3 of my data here. Let me just predict that, in the remaining data that I am collecting, for duplicates, the scale will be in the range of 0 to .2 (i.e., close to .11), and for non-duplicates, the scale will be greater than .8 (i.e., close to .87). I will also test the reliability of the symbolic threat scale, let me just predict that the reliability for duplicates will be under .2 (i.e., close to -.01.) and for non-duplicates, it will be greater than .7 (i.e., close to.81). 2. The distribution of measures with known/expected distribution I asked my participants their feeling toward KKK and the Nazi party from 0=most unfavorable to 100=most favorable, and 50 is mid point. I predict that for duplicates, the mean responses for KKK and Nazi will be close to 60 and for non-duplicates, they will be close to 8.5. 3. Measures that are known/expected to be correlated I predict that for non duplicates, the correlation between feeling toward liberal politicians with ideology and party identification are significant (p<.001) at the magnitude of about above .5 (i.e., at-.59 and r=-.57). For duplicates, I predict these relationships will be non-significant. For conservative politicians, the current data is a little more messy, although I have some speculation for why that I will try to confirm more latter. I think it likely has something to do with whether questions are coded in the same direction , but I am not making any predictions for conservative politicians for now. 4. Qualitative responses Let me just predict that for duplicates “good“ of any kind will appear for about 25% (i.e., close to 26.6%) and “nice” of any kind will appear for about 20% (i.e., close to 21%). I predict that they will occur less than 3% for non-duplicates. I anticipate (though not predict) that there are a lot more “very” for duplicates. I also anticipate that most of the “good” or “nice” not detected by the GPS method will also give KKK or Nazi values close to 50 instead of below 10. 8/10/2018 7 Comments A Proposed Procedure for Testing the Evidentiary Value of Responses from Duplicated GPS Sources (comments invited)Many of us have found a notable amount of duplicated GPS (not IP) in our recent Mturk data. Circumstantial evidence and reports suggest that responses from them is random and unreliable. The following procedure is proposed to test the evidentiary value of responses from duplicates and to determine if they are truly random or unreliable. I am inviting open comments to this procedure. I will revise the procedure based on the comments, and distribute the survey around next Friday. The overall format is similar to what I described here.
Here are the four tests that I am proposing: 1. Testing the reliability of known scales. Researchers will pick a well validated scale from their surveys with known reliability. I recommend picking a scale that includes 50% of reverse coded items. Researchers will report the reliability of the scale for duplicates and non-duplicates separately. 2. Testing the distribution of known measures. Researchers will pick a measure used in their data that has a known or expected skewed distribution (the more skewed the better). Researchers will report the distribution of the measures for duplicates and non-duplicates separately. 3. Testing relationships between variables that are known to correlate. Researchers will pick two variables used in their data that are known to correlate. For this task, I recommend looking for two measures that are known to be strongly correlated. I also recommend picking two measures that both include 50% of reverse coded items if possible, and I also recommend these two measures to be on different pages the survey. 4. Comparing the frequency of suspicious key words. It appears that duplicates tend to enter phrases that include the word “good” “nice” and “very” regardless what is asked (see footnote 1). Therefore, researchers who have open-ended questions in their survey can count how many “good” “nice” and “very” are from duplicates and how many of them are from non-duplicates. I am most interested in focusing on “good” and “nice,” given their representativeness. For test 1-3, I intend to also collect analyses of a random subset of non-duplicates that has the size of N comparable to that of duplicates. This is done so that the non-duplicates do not have any unfair advantage because of higher N. Conclusion I think we would have strong evidence that responses from GPS duplicates have limited evidentially value if a preponderant amount of analyses show a large discrepancy between responses from duplicates and non-duplicates regarding 1. the reliability of known scales, 2. the distributions or central tendency of known measures, 3. the correlations between variables that are known to correlate, and 4. the frequency of suspicious key words. __________________________________________ Footnote 1: Regarding responses to open ended questions: I included the raw response to the open-ended question in my own survey (which is still collecting data) here. Among the 282 response from duplicates, “good” appears 75 times (26.6%), “nice” appears 59 times (21%), and “very” appears 19 times (6.7%). In contrast, among the 296 responses from non-duplicates, “good” shows up only 2 times, “nice“ shows up only 1 time, and “very” did not show up. I think these three responses (two responses that have "good" and one that has "nice") are random responses that were missed using the GPS method. I looked at their response pattern, and I found that their feeling toward KKK and Nazi party (from 0 to 100) are all close to 50, which comports with the pattern seen in the responses flagged using the GPS method. As I mentioned earlier, the average feeling toward KKK and Nazi is between 8 and 9 among typical non-duplicates. I noticed that the same words do not usually appear more than once in the same open-ended response, so just counting the total presence of a word seems to be a reliable way to count how many participants have given that word. My open-ended question is an invitation for comments to the survey. 8/8/2018 83 Comments Evidence that A Large Amount of Low Quality Responses on MTurk Can Be Detected with Repeated GPS CoordinatesSuggested Citation: Bai, H. (2018) Evidence that A Large Amount of Low Quality Responses on MTurk Can Be Detected with Repeated GPS Coordinates. Retrieved from: https://www.maxhuibai.com/blog/evidence-that-responses-from-repeating-gps-are-random Backgrounds: In the past day or two, I discovered that a large number of responses in my latest Mturk survey appear to be random responses. I detect that a large portion of these random responses have repeating GPS locations. So far, a relatively large number of social psychological researchers also seem to have noticed a drop of data quality in their Mturk data and detected concerning patterns using the GPS method (see the related discussion threads on Facebook PsychMAP). What is being done now I am hoping to organize an effort to determine the scale and the nature of this problem, and I need the help from as many people/labs as possible. If you have found potential contamination (see below), I hope you can fill out this survey https://umn.qualtrics.com/jfe/form/SV_3jWIfYENfFUQ1ff. I will post an update/summary of whatever I have by then on Wednesday August 15 2018. However, the survey will keep open. How to find out if your data is contaminated One simple way to quickly determine if you data is potentially contaminated is to search for “88639831” in your data (the last digit can be different due to rounding and program used). This is the number after the decimal point for the latitude of a GPS location. This location was seen in multiple surveys. If you have it in your data, you might want to consider looking at how many participants have repeating/same GPS coordinates and analyze their data separately or exclude them. Responses with this GPS location as well as any other repeating GPS locations appear to be random. What is being determined right now: Below are some items that researchers seem to care about the most. I included some very preliminary conclusions from circumstantial evidence and observations. The scale of the impact (i.e., how many surveys have been affected for how long). So far it seems that at least about 90 studies from around the world (mostly North America and Eaurope) have been affected by the issue, and the contamination can be dated back to as early as March 2018. I am hoping to organize an effort to better determine the scale and the nature of this problem, and as mentioned above, I need the help from as many people/lab as possible. If you have found potential contamination in your data, I hope you can fill out this survey https://umn.qualtrics.com/jfe/form/SV_3jWIfYENfFUQ1ff Other characteristics of the repeaters Many people have reported that they tend to respond nonsensically to open-ended questions. In my own surveys, I have seen many “good” “GOOD” “NICE!” etc. They do not appear to take much longer or shorter time to fill out my survey compared to non-repeaters. What are some effective ways to counter it. Based on the studies of my own and few others, so far it looks like IP address cannot tell much. They can pass most basic types of attention checks (selecting a particular response or typing certain phrases), but not more sophisticated ones. Some suggest that some of them seem to be able to get pass Captcha, but it is still unsure at this moment. Evidence that responses from repeating GPS are random Here are some preliminary evidence from my own data. I think these evidence suggest that the repeaters, whatever they are, are not giving meaningful responses. I am using a survey that is still collecting data (see footnote 1). It has N=578, and 282 (48.8%) of them have duplicated (repeating) GPS. Below are some analyses done separately for repeaters and non-repeaters. With more people joining this effort, I hope this conclusion will be tested with more confidence. I have seen some analyses from other scholars that have yielded similar results (e.g., timryan.web.unc.edu/2018/08/12/data-contamination-on-mturk/) . The reliability of known scales I tested the reliability of the racial identification scale (see below), the reliability for non-repeating GPSer it is .87, for repeaters it is .11. I also tested the reliability of the symbolic threat scale (see below), the reliability for non-repeating GPSer it is .81, for repeaters it is -.01. Note that these scales include reverse-coded items. I noted that if I test the reliability of the racial identification scale without reversing the items that should be reversed, its reliability is -.84 for non-repeaters and it is .58 for repeaters. With additional review of individual responses, my impression is that repeaters tend to straight-line their responses on the same side of a page, regardless if items are reverse coded or not. Therefore, data from the repeaters do not appear to be very reliable. The distribution of measures with known/expected distribution I asked my participants their feeling toward KKK and the Nazi party from 0=most unfavorable to 100=most favorable, and 50 is mid point. For non-repeating GPSer they are 8.90 and 8.21, but for repeaters they are 60.82 and 60.02. It seems to me that it is more likely that the repeaters are giving random responses than truly have found something likable about KKK and Nazi party. 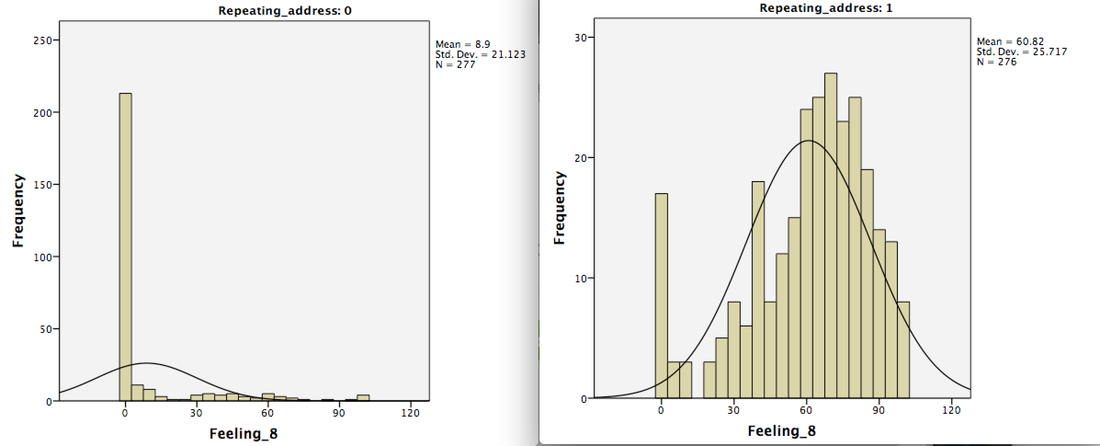 Feeling toward KKK among non-duplicates (left) and duplicates (right) 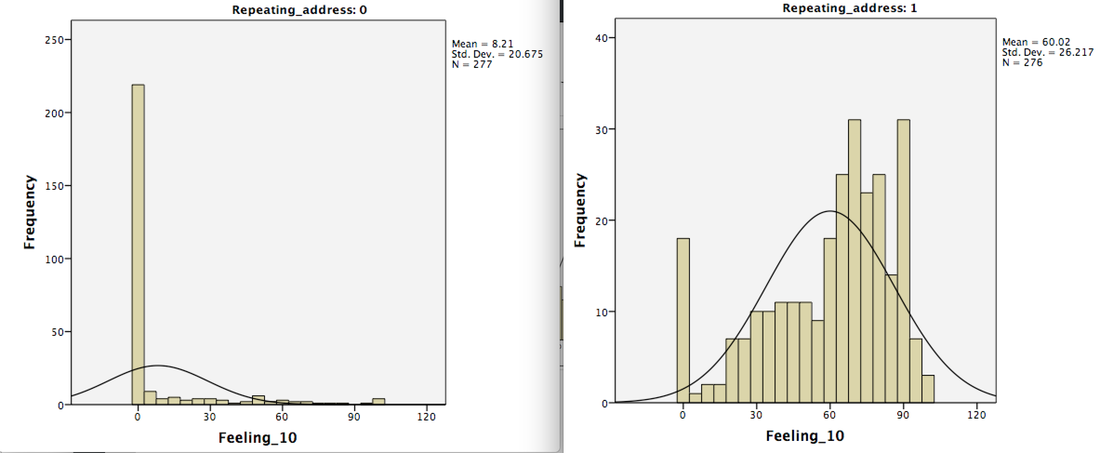 Feeling toward the Nazi Party among non-duplicates (left) and duplicates (right) Measures that are known/expected to be correlated
I used political ideology and party identification to correlate with feeling toward liberal and conservative politicians. I have four politicians who vary by ideology and religion, and religion doesn’t really matter so I combined them. The correlation between feeling toward liberal politicians with ideology and party identification are significant r=-.59*** and r=-.57*** for non-repeating GPSer. but they are not significant at all for repeaters, r=-.13 p=.14, r=.04, p=.65 . The correlation between feeling toward a conservative politicians with ideology and party identification are significant .53*** and .48*** for non-repeating GPSer. For repeaters, ideology is significant, but party ID is not r=.25** r=.10 p=.21. Therefore, the predictive power of known variables do not appear to hold up for repeaters as much as non-repeaters. Below are the measures described in my study Racial identification scale (1=strongly disagree; 7=strongly agree) ID_1r Overall, my race has very little to do with how I feel about myself.(reverse coded) ID_2 My race is an important reflection of who I am. ID_3r My race is unimportant to my sense of what kind of a person I am. (reverse coded) ID_4 In general, my race is an important part of my self-image. Symbolic threat scale (1=strongly disagree; 7=strongly agree) SYT1 The values and beliefs of other ethnic groups regarding moral issues are not compatible with the values and beliefs of my ethnic group. SYT2 The growth of other ethnic groups is undermining American culture. SYT3r The values and beliefs of other ethnic groups regarding work are compatible with the values and beliefs of my ethnic group. (reverse coded) Political ideology How would you describe your ideological preference in general? 1=very liberal; 7=very conservative Party identification How would you describe your political party preference? 1=Strong Democrat ; 7=Strong Republican Footnote 1: I preregistered hypotheses, analyses plan and all that stuff. I also planned to share data so I don’t think data peeking is an issue here |
Author(Max) Hui Bai ArchivesCategories |
 RSS Feed
RSS Feed